HieroFinder
HieroFinder
A Hieroglyphic Text Retrieval Tool

STUDY
AND PRESERVATION OF ANCIENT EGYPTIAN
Until recently, the development of information processing systems has mainly focused on contemporary languages. From a socio-economic point of view, this makes perfect sense since our needs, as users, are connected to our everyday tasks, which we develop in our languages. So, little attention has been paid to the so-called dead languages such as Ancient Egyptian. Nevertheless, our civilization was born in Mesopotamia and Egypt, and the culture of Pharaohs has fascinated us for decades and even centuries. Even nowadays, Egyptology continues to be one of the major branches of Archaeology and it is not unusual to find, from time to time, that new discoveries in this field open our news bulletins. Moreover, Egyptian is the longest-attested language, it thus becoming a particularly valuable object of research for Diachronic Linguistics. Finally, we should not forget either its intrinsic value as one of the most representative elements of one of the most important human civilizations of all time. Egyptian Hieroglyphic script is a major component of our cultural heritage and, for that very reason, we should put particular emphasis on its preservation and study.
COMPUTER PROCESSING OF HIEROGLYPHIC TEXTS
In Egyptology, computer processing of hieroglyphic texts has been closely linked to the development of classic-style text edition tools such as the old Glyph word processor or the modern JSesh system. The reason was that since there were no hieroglyphic typewriters, scholars had to rely on handwritten texts when writing and sharing documents. Even in the case of books, the hieroglyphic texts printed in their pages were typographical transcriptions or, more commonly, mere copies of those handwritten by their authors. Thus, the need for hieroglyphic text processing software was peremptory.
But, what about more complex tools such as Text Mining and Natural Language Processing (NLP) systems? In that respect, we can say that Ancient Egyptian is, basically, a virgin territory waiting to be explored.
THE HIEROFINDER SYSTEM
The HieroFinder hieroglyphic text retrieval system was developed as a M.Eng. Thesis by Ms. Estíbaliz Iglesias-Franjo, being her advisor Prof. Jesús Vilares from the Computer Science Department of the University of A Coruña. The aim of the project was to develop a Document Retrieval system capable of operating on Middle Egyptian texts. The system has been developed as a prototype (beta version) and we would like to extend and improve it in the future.
FEATURES OF THE SYSTEM
- Simplicity: Intuitive and easy to use, with a minimum learning curve.
- Flexibility: The system is able to manage both hieroglyphic and conventional text contents during indexing and querying-retrieval.
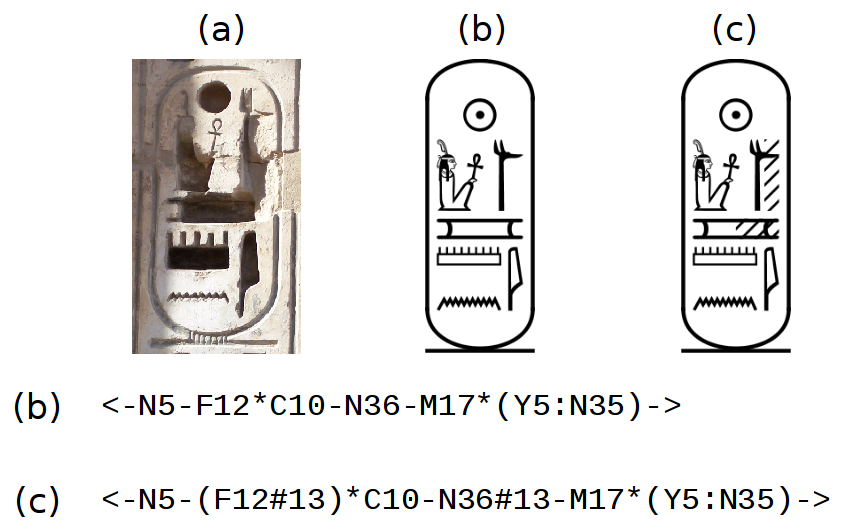
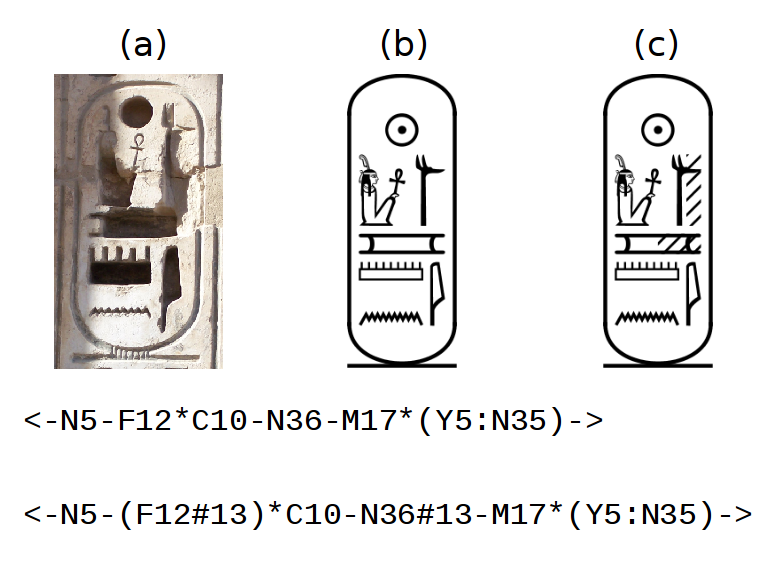
- Based on MdC encoding: Hieroglyphic text, either in documents or queries, must be encoded using Manuel de Codage (MdC) standard encoding system.
- Graphical user interface: The system provides an intuitive and easy to use front-end querying interface. It provides several options for handling the hieroglyphic text in the query, such as adding shadows, rearranging the text or inserting cartouches.
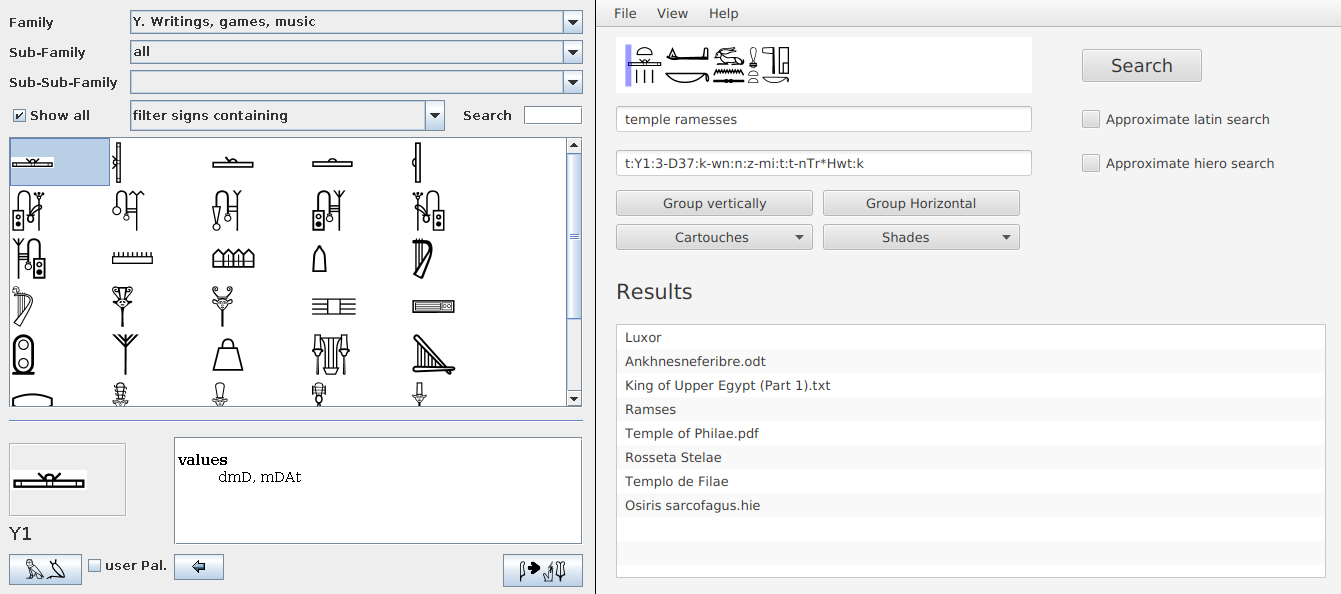
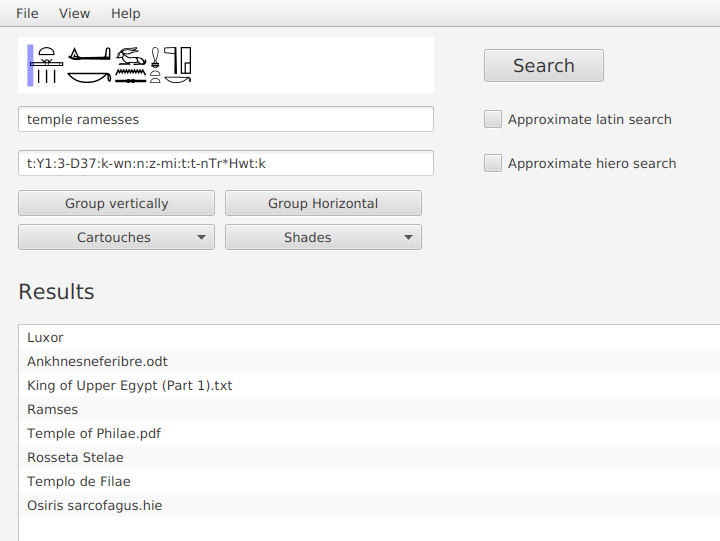
- Sign palette: If required, the user is provided with a palette of hieroglyphic signs that can be added to the query simply by clicking on them. The palette also functions as a catalog of symbols organized according to Gardiner's List classification. This palette was adapted from JSesh system.
- Exact and approximate term matching.
- Relevant document retrieval.
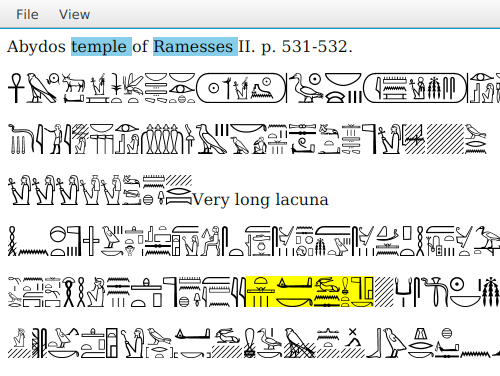
- Display of document contents: The user is able to access, from the tool itself, the content of the documents retrieved by the system. Those query term matchings found in the document are highlighted to enable the user to check why it has been retrieved.
- Simple and flexible architecture.
- Internationalization: The interface of the system supports internationalization. At this time the user can choose between English, French, Spanish and Galician.
- Implemented in Java.
- Third party libraries: HieroFinder makes use of third party libraries provided by Apache Lucene, Apache Tika and JSesh.
- Source code freely available under a LGPLv3 license.
Based on MdC encoding
Functional and intuitive
Access to contents
DOWNLOAD
Source coude freely available under a LGPLv3
license at GitHub (see below). Beware that, at this time, the
system is at prototype stage (beta version v1.0b2), although
and we intend to extend and improve it in the future.
CITING
If you use HieroFinder during the course of your research, please notify Prof. Jesús Vilares, to keep track of its users, and cite the following work (copy of the paper available here; slides available here):
Estíbaliz Iglesias-Franjo and Jesús Vilares, Searching Four-Millennia-Old Documents: A Text Retrieval System for Egyptologists. In Proceedings of the 10th ACL SIGHUM Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities (ACL LaTeCH 2016), pp. 22-31, Berlin, Germany, 2016. ISBN 978-1-945626-09-8. [Toolkit available at https://github.com/estibalizifranjo/hieroglyphs]
ACKNOWLEDGEMENTS
This work has been partially funded by the Spanish Ministry of Economy and Competitiveness (MINECO) through project FFI2014-51978-C2-2-R. We would also like to thank Prof. Josep Cervelló, Director of the Institut d'Estudis del Pròxim Orient Antic (IEPOA) of the Universitat Autònoma de Barcelona for introducing us to the Ancient Egyptian script; and Mr. Serge Rosmorduc, Associate of the Conservatoire National des Arts et Métiers (CNAM) for all his support when dealing with JSesh.